
Have you ever worked in a very large enterprise-scale SharePoint Online or OneDrive for Business environment?
I mean a Microsoft 365 tenant with 10,000 or 20,000 sites, or even 50,000 or 100,000 sites? 10 Million + files? 50,000+ users?
If you have, then you probably understand the challenges with trying to get detailed and timely analytics on your current state, including permissions for all files across all sites, or storage information for all sites and to try and figure out which groups are consuming all your space. In the past, we’d use third-party tools or PowerShell to “try” to get this data. However, the API calls to retrieve it are throttled, regardless of which solution you use. As a result, those tools and scripts will often timeout, have errors, or take so long to run that by the time you have your report it is likely out of date.
At Microsoft Build 2023, Microsoft announced that Syntex will provide some exciting new capabilities called Project Archimedes (code name) which will help to get us this data quickly and in a form that we can easily report on, across very large enterprise scale environments. Lets see what Project Archimedes is about!
Use Cases for SharePoint Analytics at Scale: A Big Data Problem
Extracting this type of data truly is a Big Data Problem! So, we need some Big Data Tools!
Project Archimedes leverages the Microsoft Graph Data Connect and Azure Synapse to copy data sets at scale to an Azure Storage Container that is owned by the same tenant. These tools are designed to operate at scale and not be subject to throttling. We’re able to get this data to our storage container much more timely (likely within a couple of hours, as opposed to multiple days or weeks) and then we can run analytics, reports and dashboards off of this storage container much more efficiently.
So, you can then quickly answer questions like:
- Are we oversharing with internal or external people?
- What is the sensitivity of all the information we are sharing externally?
- What are all the external domains we’re sharing with? And what’s the sensitivity of the information per domain?
- What permissions does a specific user have, to all files, across all sites?
- How much sharing happens at the site, library, folder or file level?
- …or any combination of these!!!
You can also answer questions related to capacity and usage like:
- Why am I running out of space in my SharePoint Online instance? Which are my largest sites? Which types of sites use the most storage?
- How much space is used by previous versions of files?
- How many sites have just one owner (when they all should have a minimum of two but also not too many owners)?
- How many sites have not changed in the last year, or last 5 years, or last 7 years?
- Which file extensions are used most, and which ones should not be in my tenant (ex. exe, pst, mp3, thumbnail, etc)?
- Which file types use up the most storage and on which sites? How many files are over a certain size (1 GB, etc.)?
- …and again, any combination of these!
All of these are important questions when you’re managing or governing large enterprise-scale SharePoint environments. As we know, good governance of enterprise SharePoint and OneDrive environments is critical to successfully managing them and feeling confident that we’re not leaking data or exposing ourselves to risk. Its hard (or impossible) to govern these environments without good and timely data, which Project Archimedes can now provide.
Components Involved and High-Level Setup
There are several components involved and steps to follow in order to leverage Project Archimedes to capture and report on these types of analytics.
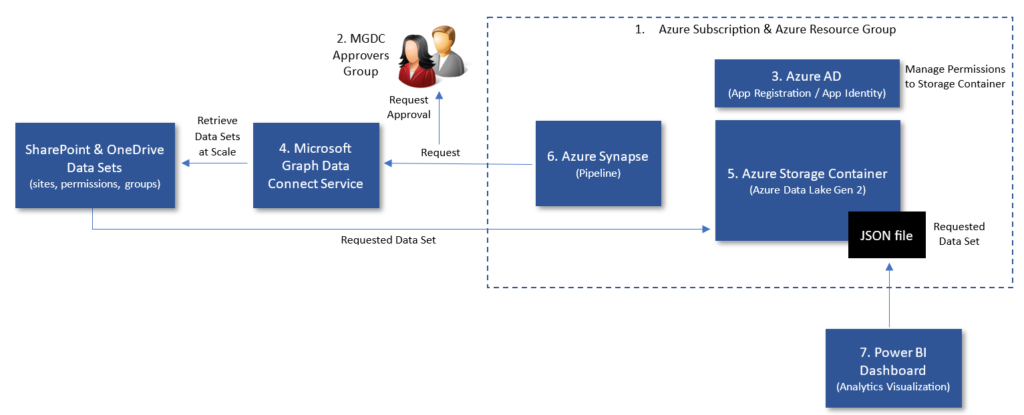
1. Azure Subscription and Azure Resource Group
- There are several Azure components involved so you will need an Azure subscription. The Azure subscription can be Azure Pay as you Go.
- It must be in the same tenant as the Microsoft 365 tenant from which you wish to pull data, and both must be part of the same Azure AD tenancy.
- We recommend that you create a new Azure Resource Group for this subscription and assign the Azure components involved below to it, with the appropriate RBAC controls.
2. Approvers Group (mail-enabled security group)
- Every request to the Microsoft Graph Data Connect service to retrieve data will require an approval. We must create a mail-enabled security group in Azure AD which contains the users that can approve a request. I have called mine MGDC Approvers.
- The user that submits the request to extract data cannot themselves approve it.
- All of the users in the Approvers group must either have the Global Reader or Global Administrator role.
3. Application Registration in Azure AD
- An application in Azure AD will be needed with some basic permissions assigned. You will also need an application identity and a secret for authentication.
- When registering the application, select to use a Client Secret and note down the client secret to use later.
- Also note down the application (client) ID because you’ll need that later as well.
IMPORTANT: there are additional detailed steps required here, which are provided in the link below to Jose’s step by step instructions.
4. Microsoft Graph Data Connect
- A Microsoft 365 service that allows organizations to export data from Microsoft 365 in bulk without throttling limits!
- A global administrator must enable the Microsoft Graph Data Connect service in the Microsoft 365 Admin Center, under: Settings > Org Settings > Microsoft Graph Data Connect.
- When enabling it, ensure that you select the MGDC Approvers group specified above and check on the SharePoint Online and OneDrive checkbox.
- Once enabled and you click Save, you need to wait 48 hours before the service is available.
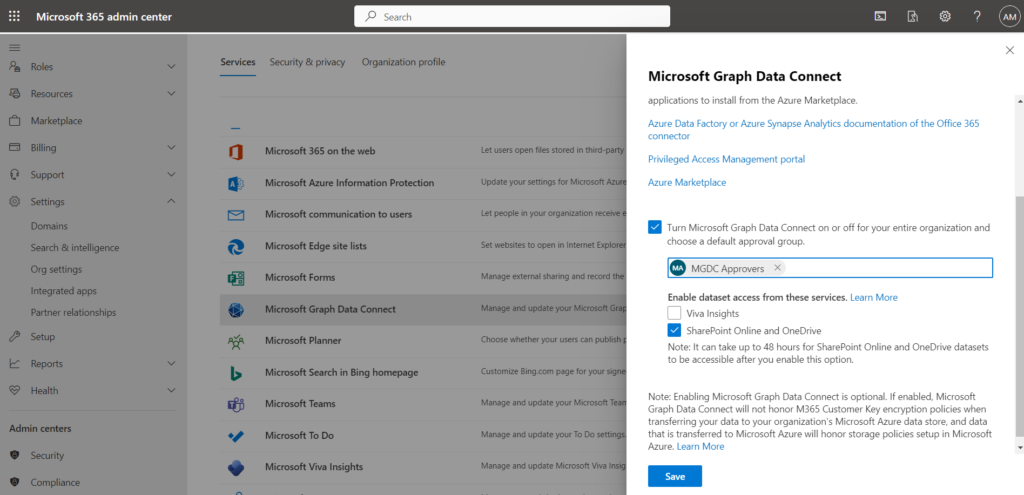
- Notice there is a link in that panel to Privileged Access Management portal – that is where requests to the Microsoft Graph Data Connect are approved by members of the MGDC Approvers group. You can also access that page through the URL
5. Azure Storage Container
- Create a new Azure Storage Container (also called an Azure Storage Account) which is where Azure Synapse will copy all the data retrieved.
- Ensure that when creating it, it is an Azure Data Lake Gen2 storage account. When selecting Azure Data Lake Gen2, check “Enable Hierarchical namespace”
- When creating it, select a storage account name, the Azure Subscription and Resource Group created above, along with your region and the ‘Standard’ type.
- Ensure your storage account name is lowercase letters and numbers only.
- Select the region which matches the region of your M365 tenant.
- Use the application (client) ID saved above when registering the application to grant it permissions to write to this storage account. To do this, you will need to add a Role Assignment.
- Create a container and folder in the Azure Storage Account.
IMPORTANT: there are additional detailed steps required here, which are provided in the link below to Jose’s step by step instructions.
6. Azure Synapse
- Azure Synapse is an enterprise grade analytics service that quickly brings data into data warehouses and big data systems. Synapse can do many things, but of our purposes here we will use Synapse to create a data pipeline that will copy data from SharePoint data sets to the Azure Storage container we created.
- You start by launching the Azure Synapse Analytics service and creating an Azure Synapse workspace. Here you enter the Azure Subscription and Azure Resource Group created above.
- You must use a region that matches the region of your Microsoft 365 tenant.
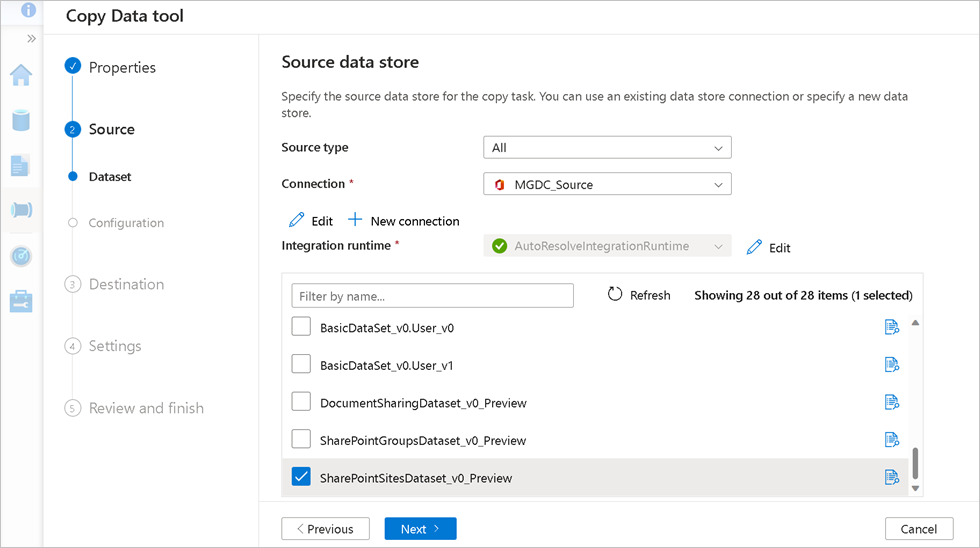
- Here its just a few quick steps to configure the Copy Data tool within your Azure Synapse Workspace and select “Microsoft 365 (Office 365)” as your data source.
- Here is where you select the data set that you want to query. There are several, but for our purposes here, two really important ones are:
- The SharePoint Sites data set SharePointSitesDataset_v0_Preview
- The SharePoint Permissions data set DocumentSharingDataset_v0_Preview
- The SharePoint Group data set SharePointGroupsDataset_v0_Preview
- You will then define the Destination Data Store as your Azure Storage Container configured above (Azure Data Lake Gen2).
- Finally, you deploy and trigger the pipeline to run in the workspace.
- From here you can monitor the pipeline’s current status and how it is running. At first you will see the pipeline’s status as ConsentPending which means that the data request needs to be approved in the Privileged Access Management portal mentioned above.
- Have someone in the MGDC Approvers group approve the request – REMEMBER: the user approving the request must be a different user from the one that deployed and triggered the request.
IMPORTANT: there are additional detailed steps required here, which are provided in the link below to Jose’s step by step instructions.
Once the pipeline has finished, the data will be in the Azure Storage Container, in the folder specified when the pipeline’s destination data store was configured. The data will be stored in one or more very large JSON files.
7. Power BI
- Power BI is of course our way of visualizing our data to answer some of the questions we asked above.
- We can configure Power BI to connect directly to our Azure Storage Container, to the JSON file created by the Azure Synapse pipeline.
- From here we can build our Power BI dashboard using the Power BI Desktop application.
- The schema for the Site Data Set can be found here, which describes all of the properties included: dataconnect-solutions/SharePointSitesDataset_v0_Preview.md at main · microsoftgraph/dataconnect-solutions · GitHub. Some key site properties you can report on across all your sites are:
- StorageUsed
- GeoLocation
- IsTeamsConnectedSite
- IsTeamsChannelSite
- IsHubSite and HubSiteId
- Sensitivity label for the site (SensitivityLabelInfo)
- User experience on unmanaged devices (BlockAccessFromUnmanagedDevices, BlockDownloadOfAllFilesOnUnmanagedDevices, BlockDownloadOfViewableFilesOnUnmanagedDevices)
- Owners
- etc… there are a lot more
- The schema for the SharePoint Sharing Data Set can be found here, with all of its properties: dataconnect-solutions/DocumentSharingDataset_v0_Preview.md at main · microsoftgraph/dataconnect-solutions · GitHub.
Great Resources for More Info
Much of the information on Project Archimedes comes from the excellent technical articles posted by Jose Barreto, Principle Product Manager at Microsoft responsible for Project Archimedes. You can find his blog here joseabarreto – Jose Barreto’s Blog (home.blog) which has tons of resources on how to setup and use Project Archimedes. Big thank you to Jose for all the information he has shared.
Some of those key resources are:
- Step-by-step instructions for setting it up: Step-by-step: Gathering a detailed dataset on your SharePoint Sites – Jose Barreto’s Blog (home.blog)
- Recent YouTube Demo: Microsoft Graph Data Connect for SharePoint – M365 Conference Demo – Jose Barreto’s Blog (home.blog)
- Power BI Sample Dashboard to visualize the data coming in from the pipeline: dataconnect-solutions/ARMTemplates/MGDC Extraction Pre Reqs at main · microsoftgraph/dataconnect-solutions · GitHub. For example:
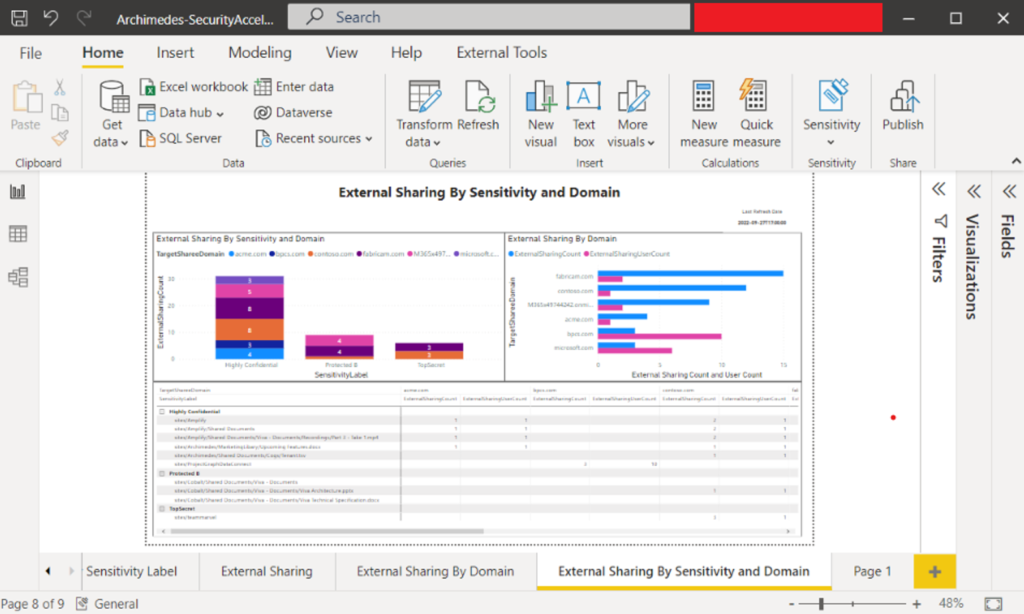
Regions
You’ll notice throughout this blog it says that regions for your Azure components and your Microsoft 365 tenant have to match. So you need both your Azure region and your Microsoft 365 region to be supported. You can check if your region is supported by Microsoft Graph Data Connect here: Datasets, regions, and sinks supported by Microsoft Graph Data Connect – Microsoft Graph | Microsoft Learn.
Deltas
When running your first extract of data, you are likely pulling all data from the data set through the pipeline and this can be thousands or millions of data objects. Even though Project Archimedes is meant to run at scale, this can still take meaningful time, storage space and cost. Microsoft Graph Data Connect also supports delta data sets, where you can pull partial data sets which include only the objects that have changed since a particular date. To configure this goes beyond the scope of this blog article, but check back later for more information on this topic.
Conclusion
Project Archimedes is a game changer as far as our ability to gather analytics and report on our large enterprise SharePoint environments. As a result, its also a game changer on how we can govern these environments because we can now gather timely and comprehensive data.
Its currently in private preview, but will be going into public preview in July. If you manage a large SharePoint or OneDrive environment, I highly recommend you give it a try! Please check back here for more resources and demos which I will post in the coming months.
Enjoy Project Archimedes!
-Antonio